Posté par: admin Il y a 13 années, 1 mois
Présentation de Luna Park:
«Luna Park» est une œuvre pour théâtre musical d’une durée d’environ une heure, (composition de Georges Aperghis, scénographie de Daniel Levy), et dont l’informatique musicale a été réalisée par Grégory Beller. Cette œuvre sollicite à différents niveaux le paradigme de la synthèse concaténative, tant par sa forme que dans les procédés qu’elle utilise. La synthèse concaténative et la transformation prosodique de la voix sont utilisées, contrôlées et déclenchées par des données gestuelles, et ce, grâce à la programmation en temps réel via des accéléromètres spécialement conçus pour cette création. La création mondiale de «Luna Park» a eu lieu à Paris, à l’espace de projection de l’IRCAM le 10 juin 2011 dans le cadre du festival AGORA 2011. Les quatre interprètes sont Eva Furrer (flûte Octobasse et voix), Johanne Saunier (danse et voix), Mike Schmidt (flûte basse et voix), et Richard Dubelsky (percussions virtuelles et voix).
Percussions aériennes:
Dans «Luna Park», Richard Dubelsky parle littéralement avec les mains en jouant sur des percussions virtuelles. Deux capteurs de mouvements conçus par Emmanuel Flety sont reliés aux mains de l’interprète lui permettant de déclencher et de moduler les sons en temps réel.
[jwplayer mediaid="2146"]
Ces sons proviennent d'enregistrements segmentés au préalable et sont lus grâce aux objets de la bibliothèque Mubu pour Max. Dans le cas de sons de flûte ou autres sons instrumentaux, le choix des sons préenregistrés s'effectue de manière aléatoire. Dans le cas de sons de source vocale, par exemple les syllabes, le choix est dirigé vers une interface permettant de favoriser certains choix plutôt que d'autres.
Synthèse de parole en temps réel:
La synthèse TTS de la parole en temps réel n’a de sens que si le texte est généré en temps réel. Dans «Luna Park», plusieurs paradigmes (HMM, Ngram, KNN...) sont utilisés pour générer de tels textes. La figure suivante montre un enregistrement segmenté en syllabes (partie supérieure), un histogramme relatif à chaque symbole représentant la fréquence d’apparition (partie centrale) et le même histogramme édité permettant de modifier la probabilité d’apparition des syllabes (partie inférieure), comme par exemple, un tirage équiprobable de syllabes «ni», «naR» et «noR».
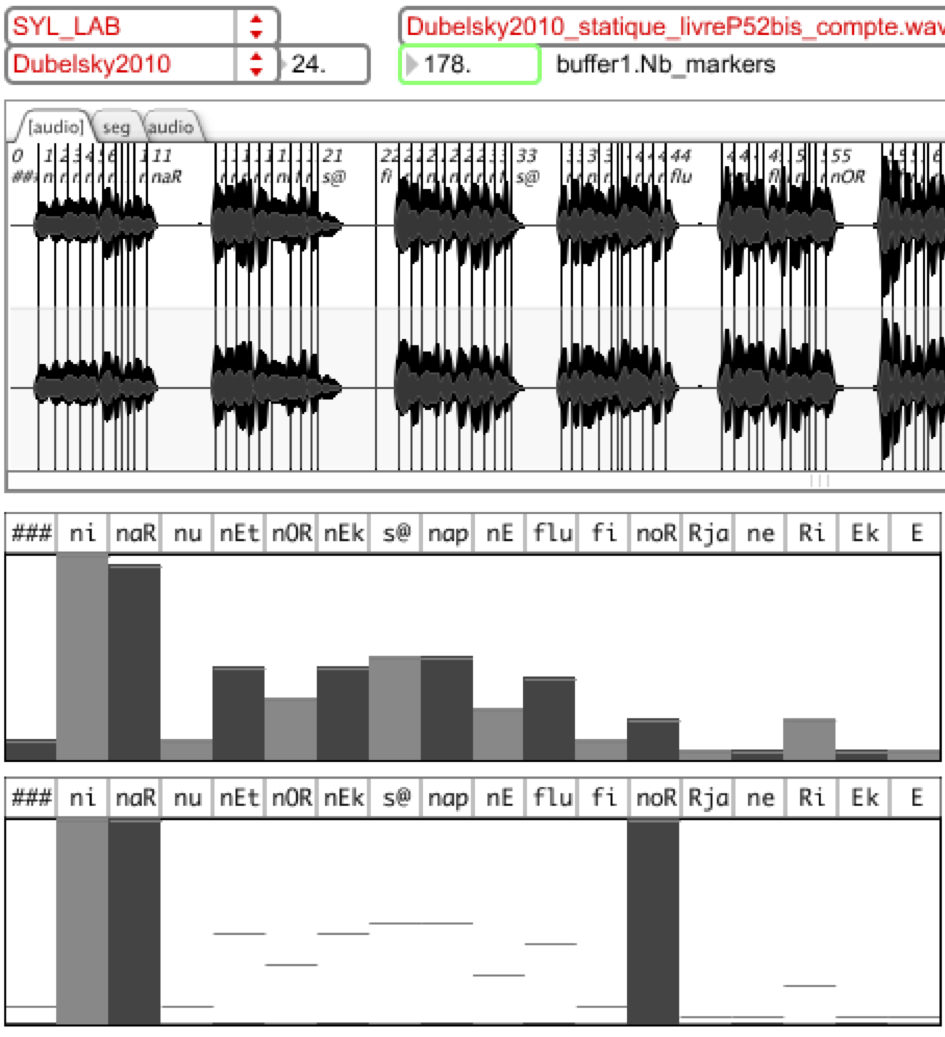
L’interface de MuBu permet notamment de rester fidèle ou de s'écarter des markers des fréquences de l'enregistrement initial. En faisant varier cette répartition fréquentielle dans le temps, on peut arriver à passer d’une répartition structurée à une répartition aléatoire de manière homogène.
Exemples de Mapping
Le mapping consiste à associer les données issues des contrôleurs gestuels avec les paramètres des moteurs audio. Nous donnons ici quelques exemples de mapping réalisés pour Luna Park :
Prosodie virtuelle
En associant directement le "Hit energy" du gant droit du percussionniste au déclenchement de la synthèse, ce dernier peut contrôler le débit de la voix parlée par les mouvements percussifs de sa main droite. Dans le cas où la rotation de la main gauche serait affectée à la transposition et à l’intensité de la synthèse, l’interprète peut alors contrôler la prosodie de celle-ci avec les deux mains.
Il faut être sage pour comprendre
Dans certaines parties de l’œuvre, l’accumulation d’énergie résultant du geste des mains du percussionniste est utilisée pour le contrôle de la synthèse concaténative. Le déclenchement de la synthèse est alors automatique, un flux ininterrompu, où chaque fin de segment (dans ce cas, des phonèmes) en déclenche un autre successivement. Plus l’énergie gestuelle fournie par le percussionniste est grande, plus l’ordre des segments est aléatoire.
Pour en savoir plus:
On peut déduire à partir de cette phase de recherche et création plusieurs perspectives concernant la synthèse vocale en temps réel ainsi que sur la captation du geste et leurs liens respectifs. Pour en savoir plus, lire les articles suivants:
Dans une première partie, ces articles recensent les différents capteurs réalisés pour cette création et donnent des détails sur leurs développements, ainsi que sur les données qu’ils produisent. Dans une seconde partie, les moteurs audio réalisés sont décrits sous la forme de processus temps réel. Outre le moteur de synthèse concaténative, il y est présenté un moteur de transformation prosodique innovant permettant la modification du débit de la parole en temps réel. La troisième partie propose quelques exemples de mapping entre les capteurs et les moteurs audio utilisés dans l’oeuvre. Enfin, une quatrième partie permet de conclure et de proposer quelques perspectives.
Partager sur Twitter Partager sur Facebook
Commentaires
Pas de commentaires actuellement
Nouveau commentaire